Introduction to Elasticsearch
Elasticsearch is a highly scalable and distributed search and analytics engine designed to handle large volumes of structured, semi-structured, and unstructured data.
Join the DZone community and get the full member experience.
Join For FreeWhat Is Elasticsearch?
Elasticsearch is a highly scalable and distributed search and analytics engine that is built on top of the Apache Lucene search library. It is designed to handle large volumes of structured, semi-structured, and unstructured data, making it well-suited for a wide range of use cases, including search engines, log analysis, e-commerce, and security analytics.
Elasticsearch uses a distributed architecture that allows it to store and process large volumes of data across multiple nodes in a cluster. Data is indexed and stored in shards, which are distributed across nodes for improved scalability and fault tolerance. Elasticsearch also supports real-time search and analytics, allowing users to query and analyze data in near real time.
One of the key features of Elasticsearch is its powerful search capabilities. It supports a wide range of search queries, including full-text search, geospatial search, etc. It also provides support for advanced analytics features such as aggregations, metrics, and data visualization.
Elasticsearch is often used in conjunction with other tools in the Elastic Stack, including Logstash for data collection and processing and Kibana for data visualization and analysis. Together, these tools provide a comprehensive solution for search and analytics that can be used for a wide range of applications and use cases.
What Is Apache Lucene?
Apache Lucene is an open-source search library that provides powerful text search and indexing capabilities. It is widely used by developers and organizations to build search applications, ranging from search engines to e-commerce platforms.
Lucene works by indexing the text content of documents and storing the index in a structured format that can be searched efficiently. The index is composed of a series of inverted lists, which provide mappings between terms and the documents that contain them. When a search query is submitted, Lucene uses the index to quickly retrieve the documents that match the query.
In addition to its core search and indexing capabilities, Lucene provides a range of advanced features, including support for fuzzy search and spatial search. It also provides tools for highlighting search results and ranking search results based on relevance.
Lucene is used by a wide range of organizations and projects, including Elasticsearch. Its rich set of features, flexibility, and extensibility make it a popular choice for building search applications of all kinds.
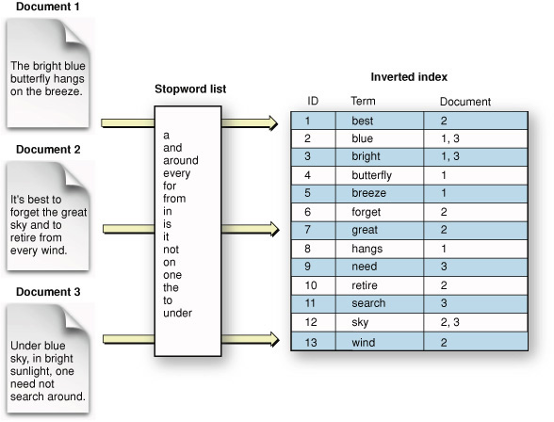
What Is Inverted Index?
Lucene's Inverted Index is a data structure used to efficiently search and retrieve text data from a collection of documents. The Inverted Index is a central feature of Lucene, and it is used to store the terms and their associated documents that make up the index.
The Inverted Index provides several benefits over other search strategies. First, it allows for fast and efficient retrieval of documents based on search terms. Second, it can handle a large amount of text data, making it well-suited for use cases with large collections of documents. Finally, it supports a wide range of advanced search features, such as fuzzy matching and stemming, that can improve the accuracy and relevance of search results.
Why Elasticsearch?
There are several reasons why Elasticsearch is a popular choice for building search and analytics applications:
Easy to scale (Distributed): Elasticsearch is built to scale horizontally out of the box. Whenever you need to increase capacity, just add more nodes, and let the cluster reorganize itself to take advantage of the extra hardware.
One server can hold one or more parts of one or more indexes, and whenever new nodes are introduced to the cluster, they are just being added to the party. Every such index, or part of it, is called a shard, and Elasticsearch shards can be moved around the cluster very easily.
Everything is one JSON call away (RESTful API): Elasticsearch is API driven. Almost any action can be performed using a simple RESTful API using JSON over HTTP. Responses are always in JSON format.
Unleashed power of Lucene under the hood: Elasticsearch uses Lucene internally to build its state-of-the-art distributed search and analytics capabilities. Since Lucene is a stable, proven technology and is continuously being added with more features and best practices, having Lucene as the underlying engine that powers Elasticsearch.
Excellent Query DSL: The REST API exposes a very complex and capable query DSL that is very easy to use. Every query is just a JSON object that can practically contain any type of query or even several of them combined. Using filtered queries, with some queries expressed as Lucene filters, helps leverage caching and thus speed up common queries or complex queries with parts that can be reused.
Multi-Tenancy: Multiple indexes can be stored on one Elasticsearch installation - node or cluster. The nice thing is you can query multiple indexes with one simple query.
Support for advanced search features (Full Text): Elasticsearch uses Lucene under the covers to provide the most powerful full-text search capabilities available in any open-source product. The search comes with multi-language support, a powerful query language, support for geolocation, context-aware did-you-mean suggestions, autocomplete, and search snippets. Script support in filters and scorers.
Configurable and Extensible: Many Elasticsearch configurations can be changed while Elasticsearch is running, but some will require a restart (and, in some cases, re-indexing). Most configurations can be changed using the REST API too.
Document Oriented: Store complex real-world entities in Elasticsearch as structured JSON documents. All fields are indexed by default, and all the indices can be used in a single query to return results at breathtaking speed.
Schema Free: Elasticsearch allows you to get started easily. Send a JSON document, and it will try to detect the data structure, index the data, and make it searchable.
Conflict Management: Optimistic version control can be used where needed to ensure that data is never lost due to conflicting changes from multiple processes.
Active Community: The community, other than creating nice tools and plugins, is very helpful and supportive. The overall vibe is great, and this is an important metric of any OSS project. There are also some books currently being written by community members and many blog posts around the net sharing experiences and knowledge.
Elasticsearch Architecture
The main components of Elasticsearch architecture are:
Node: A node is an instance of Elasticsearch that stores data and provides search and indexing capabilities. Nodes can be configured to be either a master node or a data node, or both. Master nodes are responsible for cluster-wide management, while data nodes store the data and perform search operations.
Cluster: A cluster is a group of one or more nodes working together to store and process data. A cluster can contain multiple indices (collections of documents) and shards (a way to distribute data across multiple nodes).
Index: An index is a collection of documents that share a similar structure. Each document is represented as a JSON object and contains one or more fields. Elasticsearch indexes all fields by default, making it easy to search and analyze data.
Shards: An index can be split into multiple shards, which are essentially smaller subsets of the index. Sharding allows for the parallel processing of data and distributed storage across multiple nodes.
Replicas: Elasticsearch can create replicas of each shard to provide fault tolerance and high availability. Replicas are copies of the original shard and can be located on different nodes.
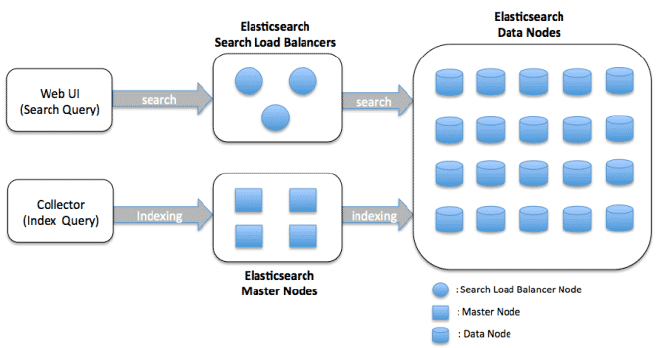
Data Node Cluster Architecture
Data nodes are responsible for storing and indexing data, as well as performing search and aggregation operations. The architecture is designed to be scalable and distributed, allowing for horizontal scaling by adding more nodes to the cluster.
Here are the main components of an Elasticsearch data node cluster architecture:
Data Node: A node is an instance of Elasticsearch that stores data and provides search and indexing capabilities. In a data node cluster, each node is responsible for storing a portion of the index data and serving search queries against that data.
Cluster State: The cluster state is a data structure that holds information about the cluster, including the list of nodes, indices, shards, and their locations. The master node is responsible for maintaining the cluster state and distributing it to all other nodes in the cluster.
Discovery and transport: Nodes in an Elasticsearch cluster communicate with each other using two protocols: discovery and transport. The discovery protocol is responsible for discovering new nodes joining the cluster or nodes that have left the cluster. The transport protocol is responsible for sending and receiving data between nodes.
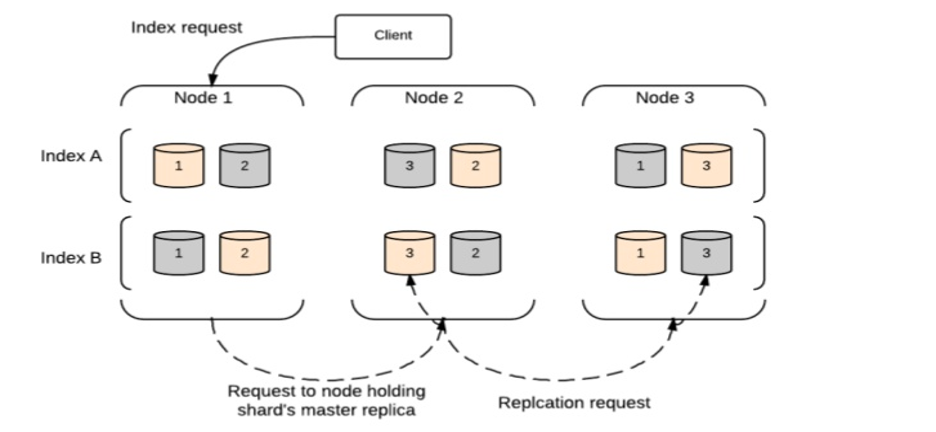
Index Request
Index request is executed as below block diagram in Elasticsearch.
Who Is Using Elasticsearch?
Few companies and organizations that use Elasticsearch:
Netflix: Netflix uses Elasticsearch to power its search and recommendations engine, allowing users to quickly find content to watch.
GitHub: GitHub uses Elasticsearch to provide fast and efficient search capabilities across their code repositories, issues, and pull requests.
Uber: Uber uses Elasticsearch to power their real-time analytics platform, allowing them to track and analyze data on its ride-hailing service in real-time.
Wikipedia: Wikipedia uses Elasticsearch to power its search engine and provide fast and accurate search results to users.
Opinions expressed by DZone contributors are their own.
Trending
-
How to Create a Microservice Architecture With Java
-
Ways To Stop and Resume Your Kafka Producer/Consumer at Run-Time
-
OneStream Architecture Explained
-
Delta, Hudi, and Iceberg: The Data Lakehouse Trifecta
Comments