A Deep Dive Into the Differences Between Kafka and Pulsar
Compare Apache Kafka and Pulsar, highlighting unique features and core distinctions. It aims to provide insight into mechanisms and inform decision-making.
Join the DZone community and get the full member experience.
Join For FreeIn this blog post, we will delve into the key differences between Apache Kafka and Apache Pulsar. By examining the core distinctions and unique features of these two messaging systems, we look to provide you with an initial understanding of their core mechanisms and implementation. We hope this analysis will not only assist you in making informed decisions when choosing between the two but also serve as a valuable resource to support further exploration and understanding of their functionalities.
MQ vs. Pub/Sub
Before diving into the differences between Pulsar and Kafka, let’s first review the historical context of Message Queues. We believe the background information contributes to your understanding of why some of the features in Kafka and Pulsar are designed in their specific ways.
Message Queues (MQ) and Publish-Subscribe (Pub/Sub) are two prevalent messaging models. MQ has a simple logic with a long history, existing in various fields, from data structures to operating system pipelines. An MQ consists of a queue that holds messages between a sender and a receiver. The characteristics of a message pipeline include:
- No data storage
- No data retention
- No consumption status tracking (cursor)

In the big data era, however, this “read-once-and-delete” model (publish one, consume one, and delete one) cannot meet the needs of data booms. A single message queue has limited throughput; when the data volume exceeds a single queue’s capacity, we need multiple business units (queues) to process the data. This is a common distributed model, and such queues are also called Message Brokers.
Brokers are programs that handle messages, acting as intermediaries independent of each other. When we have multiple brokers, each of them processes a portion of the data. If the data has no order requirement, the processing logic is very simple. This is similar to MapReduce, which allows you to divide problems and process them separately before being aggregated again. This is a classic solution when the data volume reaches a certain level.
The Maturity of the Pub/Sub Model
As data volumes grew, more and more business scenarios required distributed processing. Data might come from multiple producers, and there would be only one consumer consuming the data.
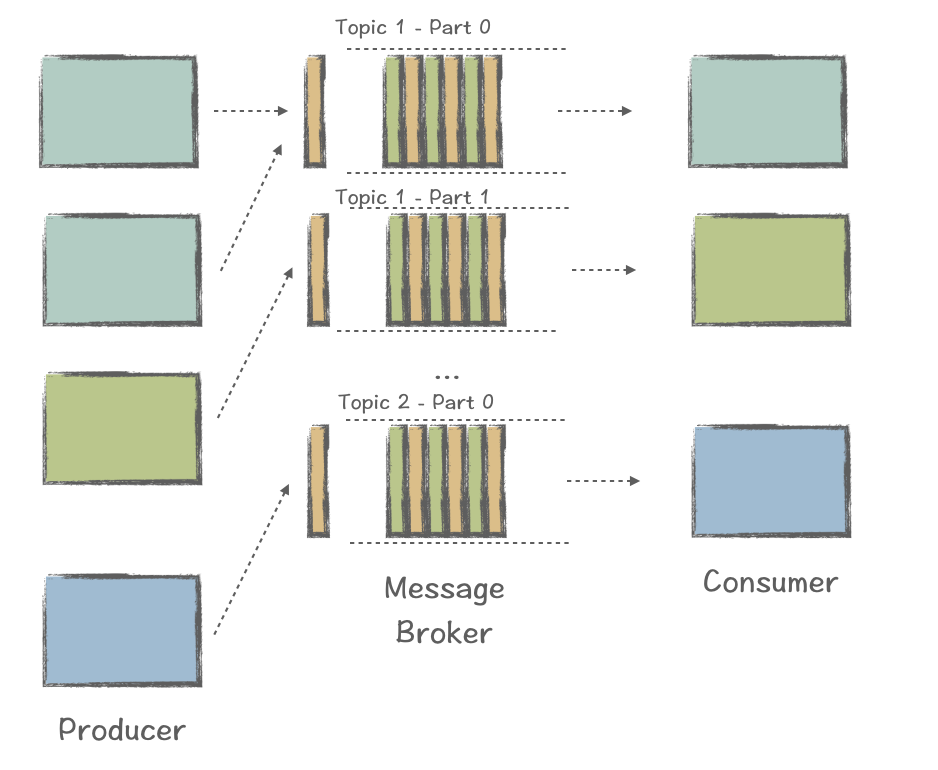
So, how did we handle this new model? Simply put, to deal with approximately 80% of the MQ scenarios (massive data processing), the model was abstracted to drive the development of new products specifically for distributed processing, including Apache Kafka.
This new model brought new market opportunities while it also faced new challenges, including:
- Massive data storage, consumption status tracking (cursors), and intermediate states storage.
- Delayed reads, duplicate reads, multiple reads, and reads from specific positions.
- Consumption isolation and resource management
- Real-time processing, high throughput, and low latency
- Transactions
- High scalability
- Enterprise features and security
To provide a more concrete example, consider a telecommunications vendor that needs to collect certain data from users nationwide. It is impossible to collect them directly from all users due to the enormous data volume. An alternative solution is to partition the data by area. After collecting independently for each partition, the data can then be aggregated. This model is very common in today’s messaging middleware solutions and led to the emergence of the industry pioneer Kafka.
Kafka did face some challenges in its early days and has continuously evolved to address market demands. Today, Kafka is considered the de-facto leader or the “tide rider” in the big data era.
Kafka: The Tide Rider
Apache Kafka implements a classic distributed system. To process a partition of data, Kafka stores the entire partition data in each node (i.e., Broker), which is responsible for both computing and storage. A partition can have multiple replicas, with corresponding copies stored in both the partition leader and in-sync replicas (ISRs). This groundbreaking distributed processing approach effectively resolved a series of challenges at the time when Kafka was born, such as peak clipping and asynchronous communications. It features high performance (high throughput and low latency) and data persistence, meeting the data migration needs of the big data era.

Over the years, a comprehensive Kafka ecosystem has formed thanks to a thriving open-source community and commercial companies backing the project. Numerous large and small enterprises have endorsed Kafka, which speaks volumes for its maturity as a product.
While Kafka’s simple architecture allowed it to grow rapidly and gain a head start, it also left room for potential difficulties in adapting to different scenarios. Some of these challenges include:
- Rebalancing pains
- Difficulty in scaling brokers, topics, partitions, and replicas
- Broker failure handling
- Latency and jitter
- Enterprise-grade features
- Cloud migration
Kafka emerged around 2010, during the initial explosion of big data. As data volumes continued to grow in subsequent years, functionality requirements and ease of use became increasingly important. More importantly, the concept of “Cloud Native” started to gain traction, which heralded new challengers to Kafka, with Apache Pulsar being a standout among them.
Pulsar: Born for Cloud-Native
Kafka’s classic architecture has inspired many successors, including Apache Pulsar. As a next-generation messaging platform for cloud-native environments, Pulsar boasts a decoupled architecture for computing and storage.
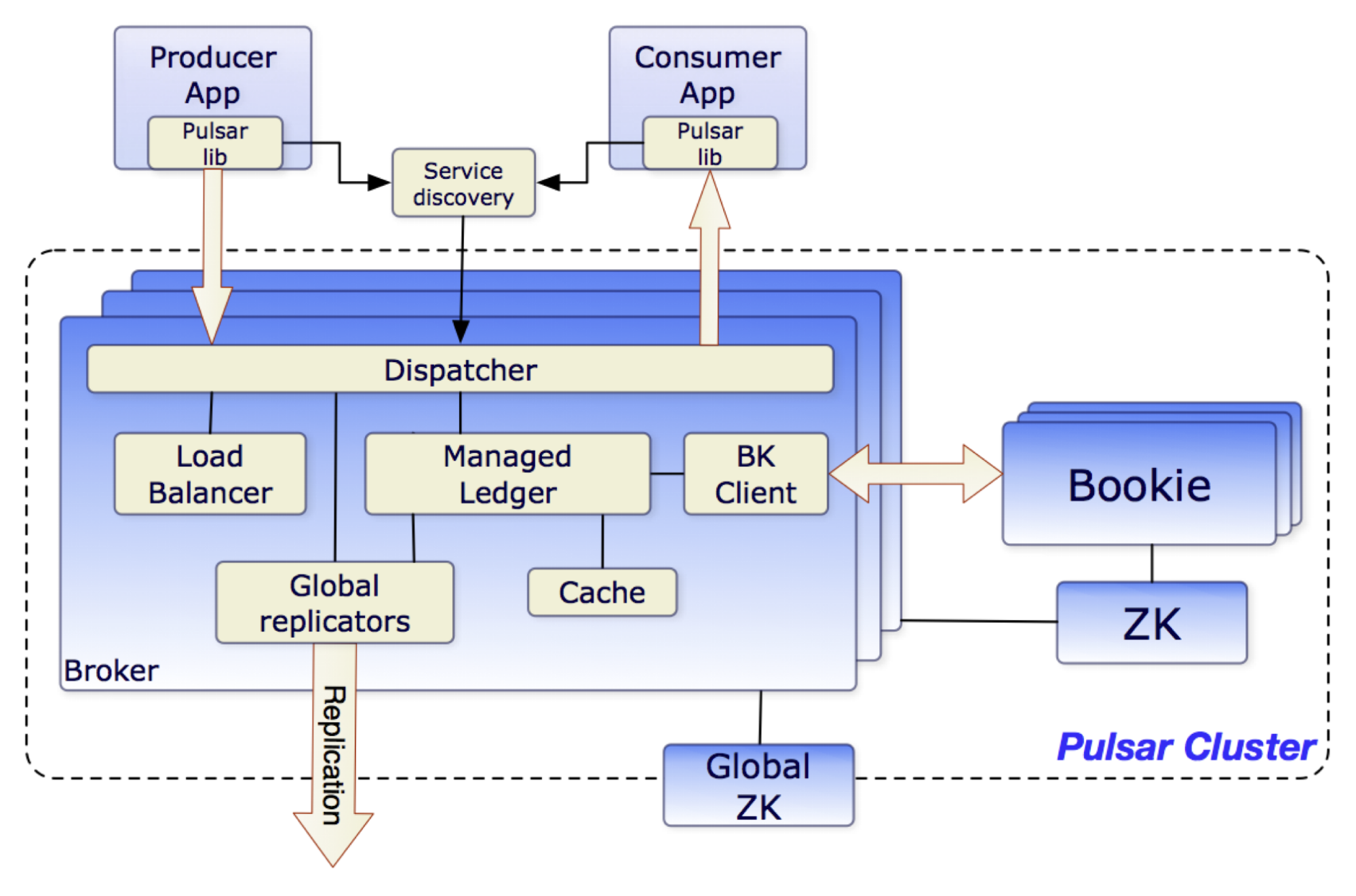
Pulsar brokers serve as the computing layer, while storage is supported by another Apache top-level project, Apache BookKeeper, a distributed write-ahead log (WAL) system. BookKeeper can efficiently handle a large number of data storage tasks, with metadata sourced from ZooKeeper.
Pulsar’s layered architecture, cloud-native compatibility, and open-source enterprise features such as multi-tenancy offer users more possibilities in production. Nevertheless, its complex structure also means higher learning costs and a lack of talent in the job market. This is also the reason why big tech companies like Tencent have endorsed Pulsar, but smaller ones have been struggling to adopt it.
Compared to Kafka, Pulsar still has a long way to go, especially in its ecosystem, but it has kept a strong momentum since its inception.
- 2012: Developed internally at Yahoo!
- 2016: Open-sourced under the Apache 2.0 license
- 2018: Became an Apache Top-Level Project (TLP)
- 2023: 600+ contributors, 12.5K+ stars, 3.3K+ forks
In 2021, Pulsar surpassed Kafka in the number of monthly active contributors. With a five-year difference in becoming a TLP (Kafka in 2013 and Pulsar in 2018), how does Pulsar solve the pain points in Kafka? What are some of the major differences between them? With the above background information, let’s review the questions in more detail.
Brokers and Partitions: Decoupled or Not
The first major difference is how both systems handle the relations between brokers and partitions. Kafka’s partitions and brokers are tightly coupled. When a producer publishes data to a Kafka cluster, it is written to a partition. Each partition has a leader node with several (or zero) followers, which replicate data in case of leader failure.
The most difficult part of this practice is data migration for partitions. If you have a large amount of data in a Kafka partition, the migration process can be a nightmare. The strong coupling relationship between partitions and brokers, to some extent, leads to a series of other issues in Kafka.
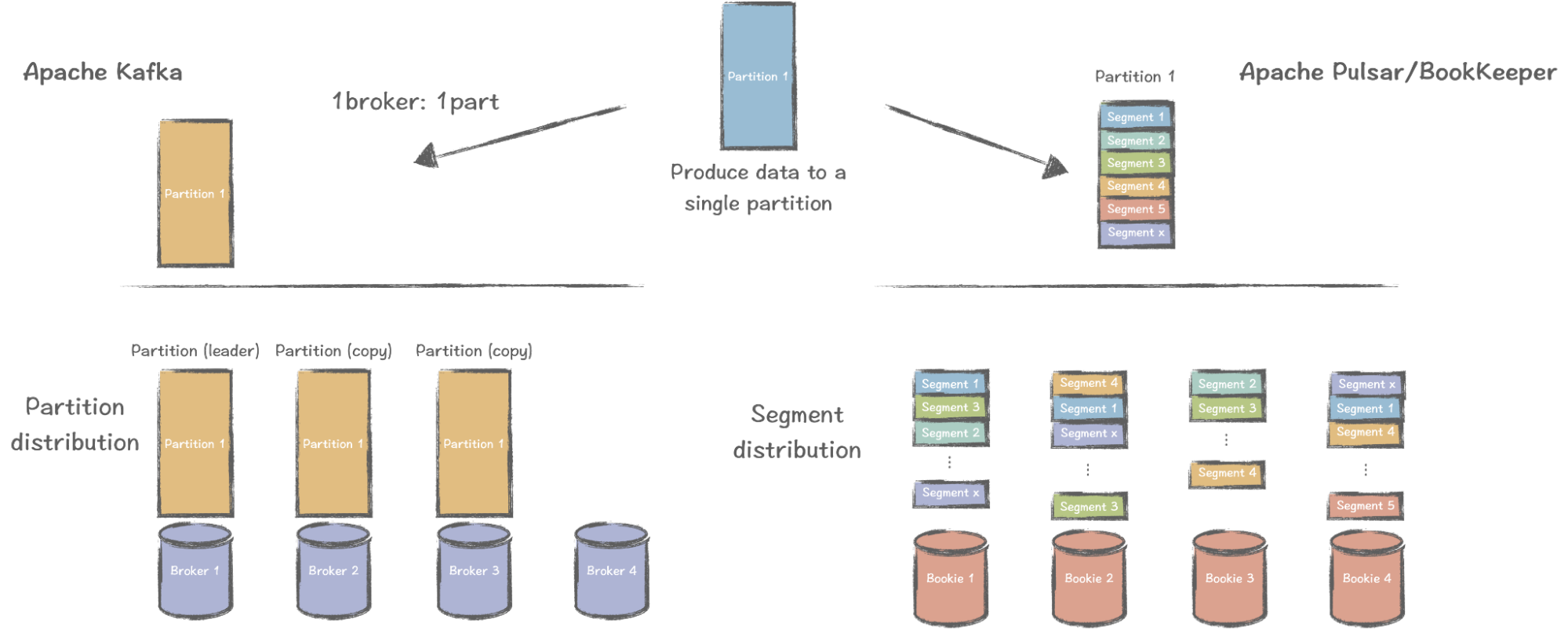
By contrast, partitions and brokers are loosely coupled in Pulsar. A partition can be further divided into segments, which allow for the striping of entries across multiple storage nodes (i.e. bookies). In other words, the data in a single partition can be stored in multiple nodes with multiple copies.
In the above image, there are many stripped data segments in Partition 1, and Segment 1 may have replicas in Bookie 1, Bookie 2, and Bookie 4. If one of the bookies fails, the impact on the partition is trivial, as it possibly affects only one or a few segments. Additionally, the recovery process is significantly faster compared with the data loss of an entire partition.
When Kafka has developed over a decade ago, it needed rapid growth and did not prioritize fine-grained data storage and management. In contrast, Pulsar provides a more sophisticated way of this aspect, which brings more room for its future growth.
Scalability
Scalability is another key factor that differentiates the two messaging systems.
In Kafka, you have multiple brokers to receive the data (one leader with several ISRs). In the event of a node failure, the partition on that broker will be lost. It requires manual maintenance (or scripts) for recovery, and the logic is relatively complex. You can’t simply replace it with a new broker, and the previous broker ID can’t be automatically transferred.
Another pain is that the new broker cannot immediately handle the old broker’s traffic because the new broker does not have the partition. You need to manually migrate the old partition to the broker. However, if you have a large data volume, the migration can be cumbersome, as mentioned in the previous section.
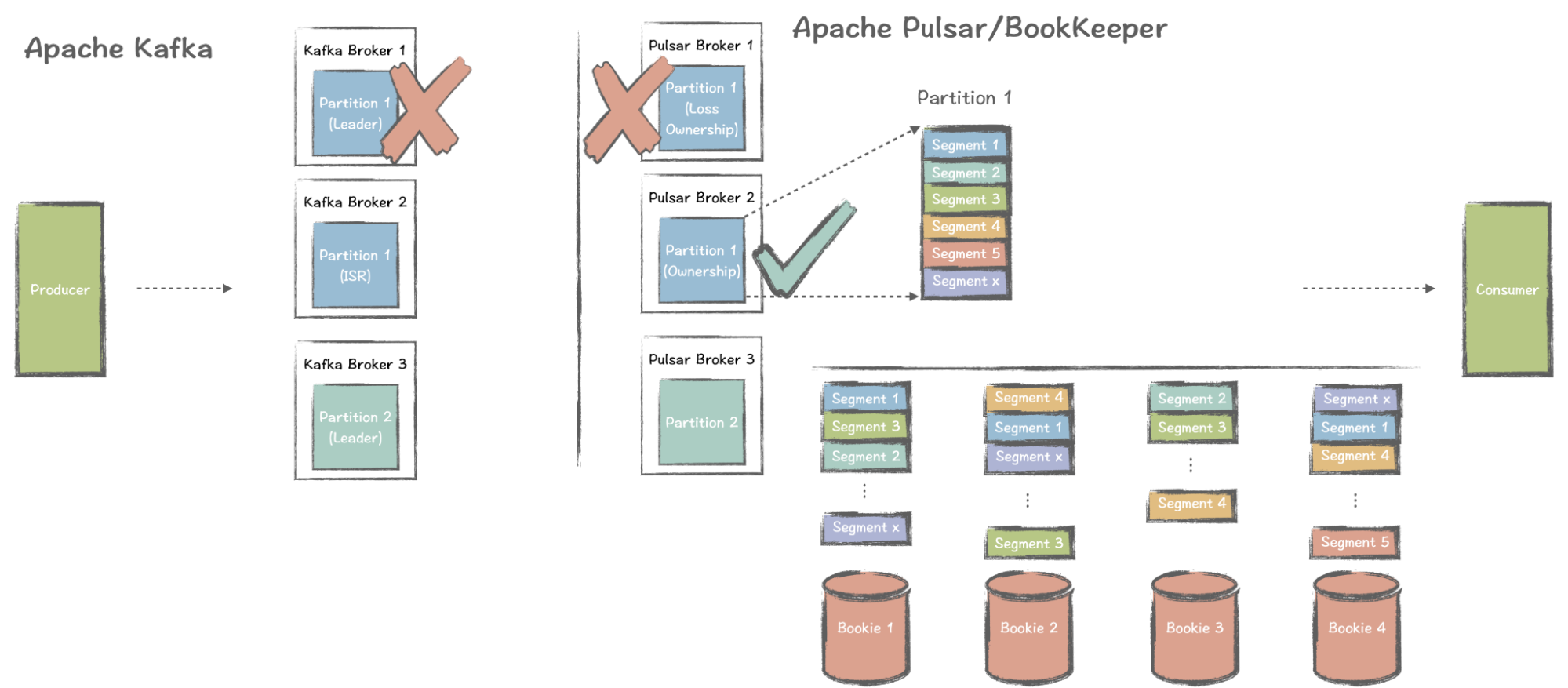
So, how does Pulsar handle the same issue?
If a Pulsar broker fails, it will lose the ownership of the partition it held before, the information of which is stored in ZooKeeper. Upon detecting the change, other brokers re-elect a new one. For the entire Pulsar cluster, a broker failure is not a significant issue, as another broker can quickly take over.
The efficiency of this process lies in the fact that Pulsar brokers are stateless. When a broker goes down, the broker cluster can be scaled immediately. Brokers do not store data and only serve as the computing layer. Bookies store the data, and they do not even need to know what happens on the broker side.
The impact of losing a hot partition in Pulsar is much less than that in Kafka, and recovery is much faster. If you need to improve the cluster’s ability to process messages, you only need to add brokers without worrying about the storage layer.
Traffic Hotspots
The ability and approach for brokers to handle traffic hotspots are different in Kafka and Pulsar.
In Kafka, when a broker has a heavy write load, increasing the number of brokers doesn’t help, as only one broker can handle the writes at a time. If the broker has a large number of reads, adding a new broker also won’t work since there are no partitions in it. Rebalancing the traffic is another tricky issue, as mentioned earlier.
Typically, there are two solutions for handling traffic hotspots in Kafka:
- Increasing the number of partitions comes with significant difficulty in rebalancing.
- Scaling up the broker to improve its performance. If the broker fails, you need to use another one to handle the heavy traffic, which also requires a scale-up (eventually the entire cluster), making it a cost-inefficient method.
In Pulsar, a write hotspot results in a significant number of stripped segments. As more data is written, the broker generates more segments and distributes them among multiple bookies. If necessary, the bookie cluster can simply scale out to store newly-add segments (also known as ledgers in BookKeeper).
For a read hotspot, Pulsar relies on bundles, each containing multiple topics to serve client requests. Each bundle is assigned to a specific broker. Bundles provide a load balancing mechanism, allowing a bundle that exceeds some preconfigured thresholds (for example, topic count and bandwidth) to be split into two new bundles, with one of them offloaded to a new broker.
Writes and Reads Implementation
How Kafka and Pulsar serve to write and read requests has a direct bearing on their latency and jitter, which are two important factors when choosing a messaging system.
Writes in Kafka rely heavily on the operating system’s page cache. Data is written directly to the page cache (memory) and then asynchronously written to disk. Kafka utilizes the Zero Copy principle, which allows data to go directly from memory to the disk file. In other words, the Kafka broker does not need to allocate an additional separate place for storing the data.
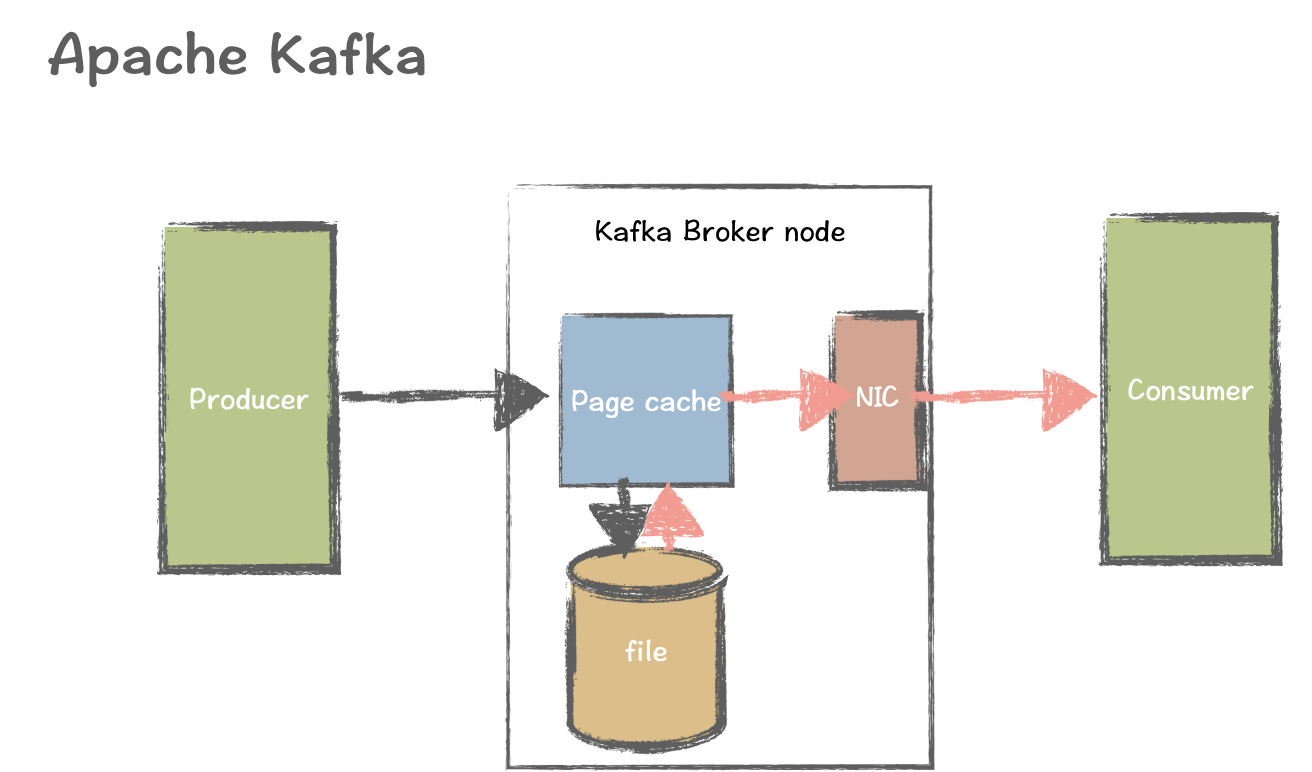
However, Kafka’s heavy reliance on the page cache can cause problems. In catch-up read scenarios, reading historical data from files requires loading the data back to memory. This can evict unread tailing reads (the latest data) from the cache, leading to inefficient swapping between memory and disk. This can impact system stability, latency, and throughput.
Pulsar handles data reads and writes differently. The Pulsar broker serves as the BookKeeper client and writes data to ledgers. The process involves writing data to a journal file (memory) as a write-ahead log and then asynchronously and sequentially writing data to the journal disk. This provides transactional management and ensures data durability, allowing for a fast rollback in case of issues.
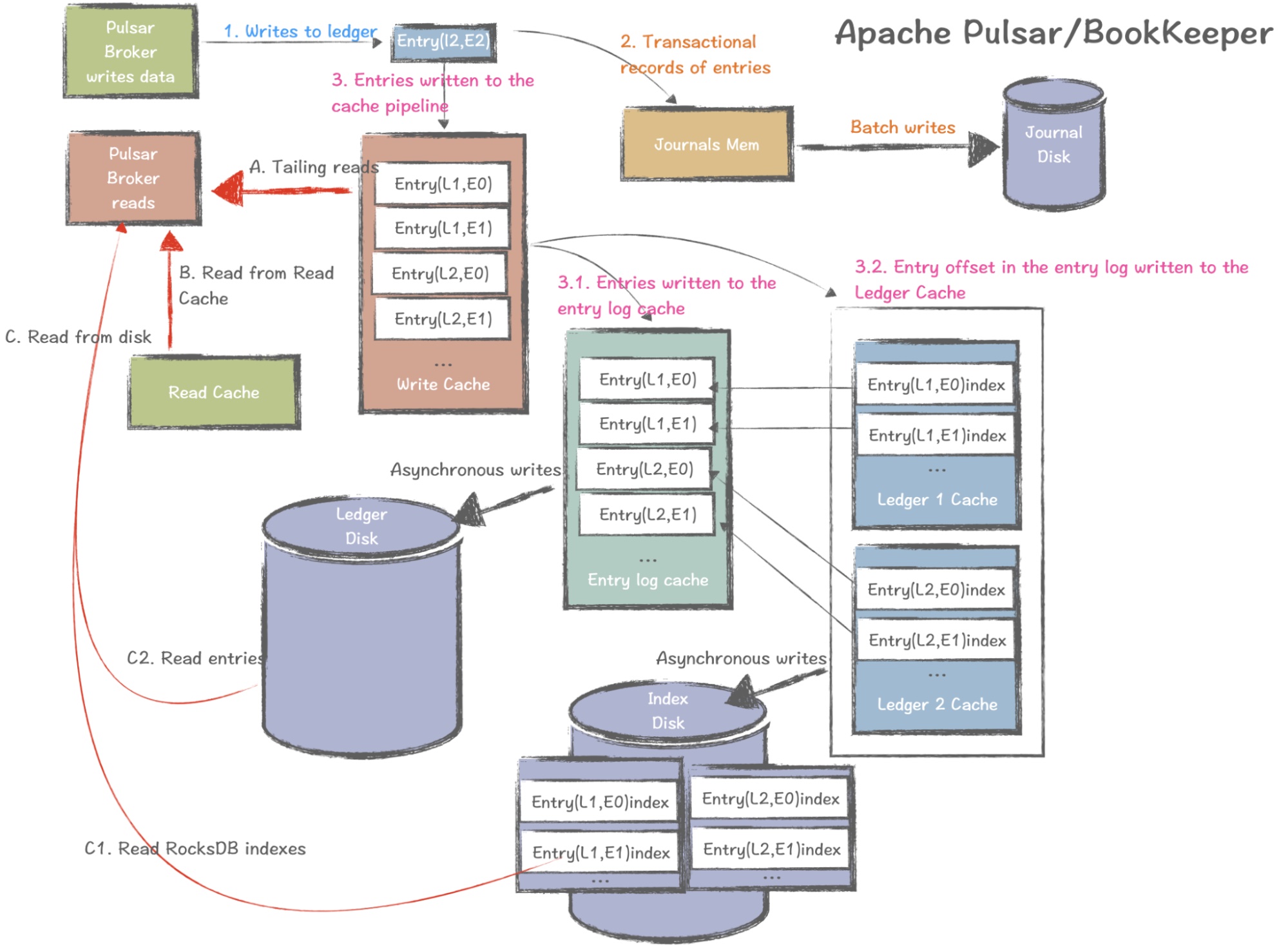
Pulsar does not use Zero Copy but instead relies on JVM off-heap memory. When transaction logs are recorded, data goes to a write cache and is then stored in two places: entry log cache, where data is asynchronously written to the ledger disk, and ledger cache, where data is asynchronously written to the index disk (stored in RocksDB).
For reads in Pulsar, if a consumer needs to read data and it happens to be in memory (hit in the write cache, which is usually the case for tailing reads), it can be directly accessed. If the data is not in the write cache, it reads from the read cache. Otherwise, the data is read from the disk according to the index stored in RocksDB. Once the data is retrieved, it is written back to the read cache. This ensures that the next time the data is requested, there is a high probability it will be found in the read cache.
Admittedly, the reading process involves many components, which can lead to extra network overhead and optimization difficulty, and sometimes pinpointing the problematic component can be challenging. Nevertheless, the benefits it brings are quite obvious. This multi-tiered architecture allows for stable data retrieval at various levels, and its JVM off-heap memory management is highly controllable (Pulsar relies less on memory compared to Kafka).
The different approaches to handling reading and writing in Kafka and Pulsar lead to different capabilities in latency and throughout.
As shown in the image below, in most cases, latency is low in Kafka as it writes to the page cache, and the memory is large enough to handle the data. However, if the data consumption rate is slow and a large amount of data remains in memory, the data needs to be swapped to disk in large chunks. If the disk speed cannot match the memory (this is true in most cases), a noticeable latency spike will occur, as the incoming data cannot be written until the memory data is swapped to the disk. This results in jitter, which can be dangerous in latency-sensitive scenarios. Although Pulsar’s latency may not be lower than Kafka’s, its stability is significantly better. Even with additional components and some performance loss, Pulsar’s overall stability is worth the trade-off.
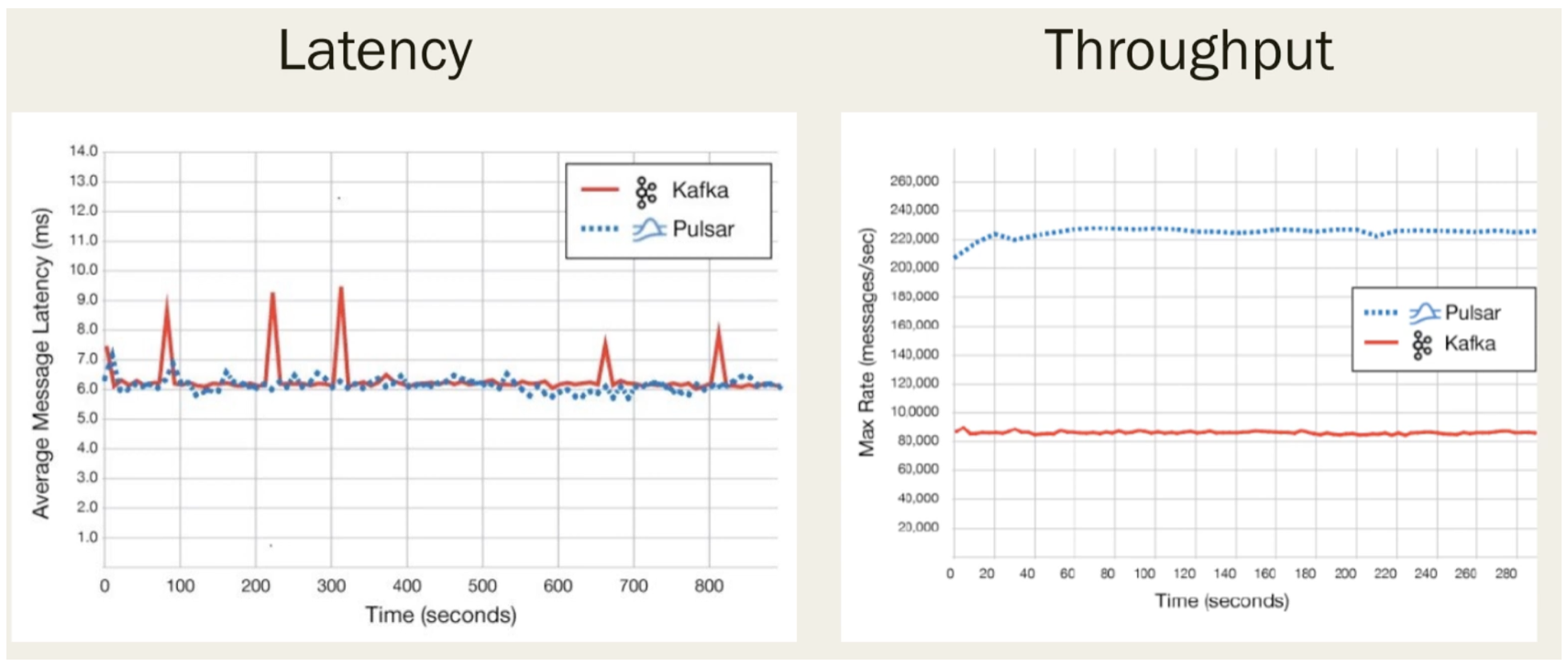
Throughput is Pulsar’s strength. Its stripped storage allows for maximum throughput performance. Theoretically, the number of bookies determines the speed of writing data to disk, which in turn determines Pulsar’s throughput. In contrast, Kafka’s throughput is limited by the speed at which individual broker nodes can write, so Pulsar’s throughput is generally superior to Kafka’s.
Enterprise-Grade Features
Now that we have discussed the different approaches that Kafka and Pulsar take to resolving some common problems in streaming and messaging, let’s review their capabilities for enterprises at a high level.
Kafka |
Pulsar |
|
Multi-tenancy |
A single-tenant system |
Built-in multi-tenancy |
Data migration |
Relies on Mirror Maker and requires additional maintenance. Vendor tools like Confluent Replicator are also available in the market. |
Built-in geo-replication, which is open-source, stable, and easy to maintain. |
Tiered storage |
Provided by vendors for commercial use. |
Built-in tiered storage that supports moving cold data to cheaper storage options, such as AWS S3 or Google Cloud Storage. |
Component dependency |
Kafka Raft (KRaft) is in early access mode as of Kafka 2.8, allowing Kafka to work without ZooKeeper. This is a significant advantage for Kafka, as it simplifies Kafka’s architecture and reduces learning costs. |
One common criticism against Pulsar is its strong dependency on ZooKeeper and the need to maintain an additional storage system, requiring operators to master more skills. |
Cloud-native deployment |
Relatively complicated |
Born for cloud-native environments as Pulsar separates compute from storage. Enterprises can install Pulsar on Kubernetes with Helm or StreamNative Pulsar Operators. |
Ecosystem |
A thriving ecosystem with a variety of tools, such as connectors. |
A growing ecosystem while it is much smaller compared with Kafka’s. StreamNative has been working to create a StreamNative Hub to store Pulsar’s ecosystem tools. |
Talent |
A large number of professionals focusing on Kafka and its ecosystem, making it a crucial factor when choosing Kafka. |
Lack of Pulsar professionals and experts. |
This table only lists some key differences that enterprises may be interested in. Pulsar also has other unique enterprise features like flexible subscription modes (exclusive, failover, shared, and key_shared) and selective acknowledgment.
Conclusion
We usually don’t make technology choices based solely on one or two factors. Even if a product has no critical flaws or weaknesses, we still need to conduct more comprehensive evaluations. Kafka and Pulsar took different paths from the outset. Kafka has more first-mover advantages in the big data field, and it is unparalleled in terms of talent pools and ecosystems. However, its architecture is relatively old, and in the cloud-native era, its competitiveness has declined when faced with the promising newcomer Pulsar. We hope this article can help you gain a better understanding of both systems and make better-informed decisions in your middleware selection process.
Opinions expressed by DZone contributors are their own.
Trending
-
Types of Software Bugs
-
Amazon Fargate For Containers
-
Building and Deploying Microservices With Spring Boot and Docker
-
Will ChatGPT and Generative AI “Replace” Testing?
Comments