Working With Neo4j Graph Database
We will explore the basic concepts of a graph database and then look at some examples of graph data modeling and querying by using Neo4j graph database
Join the DZone community and get the full member experience.
Join For FreeTraditionally, a majority of our applications relied on relational database systems (RDBMS) for their data storage needs. But RDBMS systems are not very efficient at handling high volumes of connected data. A graph database is purpose-built to store this category of connected data.
In this article, we will explore the basic concepts of a graph database and then look at some examples of graph data modeling and querying by using the Neo4j graph database.
What is a Graph
We must understand what a graph is before trying to understand a graph database:
A graph is a concept taken from graph theory in Mathematics. It is a data structure composed of a set of nodes (also called vertices) connected by a set of edges. A popular example of a graph is a social network where the members of a network are linked to each other by means of different types of relationships as shown here:

In this diagram, the members of the network are represented by nodes and the edges are the relations between them.
Each node can represent an entity (a person, place, thing, category, or another piece of data).
This graph data structure allows us to model all kinds of scenarios having connected data from a network path to a network of servers, or anything else defined by relationships. We can break down any structure or concept irrespective of complexity into a set of constituent parts that have some relationship to one another.
What is a Graph Database
We can best understand a Graph Database by thinking in terms of the data model. A traditional data model is composed of entities associated with each other with various types of relationships. We visualize this data model with an Entity Relationship Diagram (ERD).
In contrast, we store a graph data structure in a graph data model consisting of vertices or nodes that represent the entities and edges that represent the relationships between these entities.
Similar to a database management system, we perform create, read, update and delete (CRUD) operations in a graph database while working with connected data. However, since relationships are first-class citizens in graph data stores, we do not have to specify data connections using any implementation-specific technique, like foreign keys.
To get a feel of working with a graph database, let us use Neo4j which is a widely used open-source graph database.
Introducing Neo4j Graph Database
Neo4j is an open-source, NoSQL, native graph database supporting ACID transactions. It supports deployment in an environment with high availability and reliability thus making it suitable to store data in production systems. It comes with a community and enterprise edition.
Neo4j also has a good ecosystem of tools for development and for supporting operational activities. It provides drivers and integrators for a wide array of technology stacks for integrating applications running.
Installing and Starting Neo4j Graph Database
Like all databases, Neo4j Graph Database has a database server. Let us install this first by downloading the binary for our operating system from the download center and extracting the archive to a directory.
Here is a snippet of the files in our extracted archive:
.
├── bin
│ ├── cypher-shell
│ ├── neo4j
│ ├── neo4j-admin
├── certificates
├── conf
│ └── neo4j.conf
├── data
│ ├── databasesWe use the neo4j executable under the bin folder for starting and stopping the server. The neo4j-admin program is used for administration tasks like setting the master password before starting the server. The neo4j.conf file under conf folder contains the server configuration.
Before starting the server we will disable the authentication requirement by editing this configuration file.
dbms.security.auth_enabled=falseWe do this by setting the property dbms.security.auth_enabled to false.
Next, let us start the server by running the command:
./bin/neo4j consoleThis will start the Neo4j server. A snippet of the server console looks like this:
Starting Neo4j.
INFO Starting...
INFO ======== Neo4j 4.2.6 ========
INFO Performing postInitialization step for component 'security-users' with version 2 and status CURRENT
INFO Updating the initial password in component 'security-users'
INFO Bolt enabled on localhost:7687.
INFO Remote interface available at http://localhost:7474/
INFO Started.In this console log, we can see that server is started and is listening on two ports:
- on port 7687 using the Bolt protocol.
- on port 7474 using the HTTP protocol.
We will talk about Bolt in a later section on application integration. For now, let us open the HTTP URL http://localhost:7474/ in a browser:
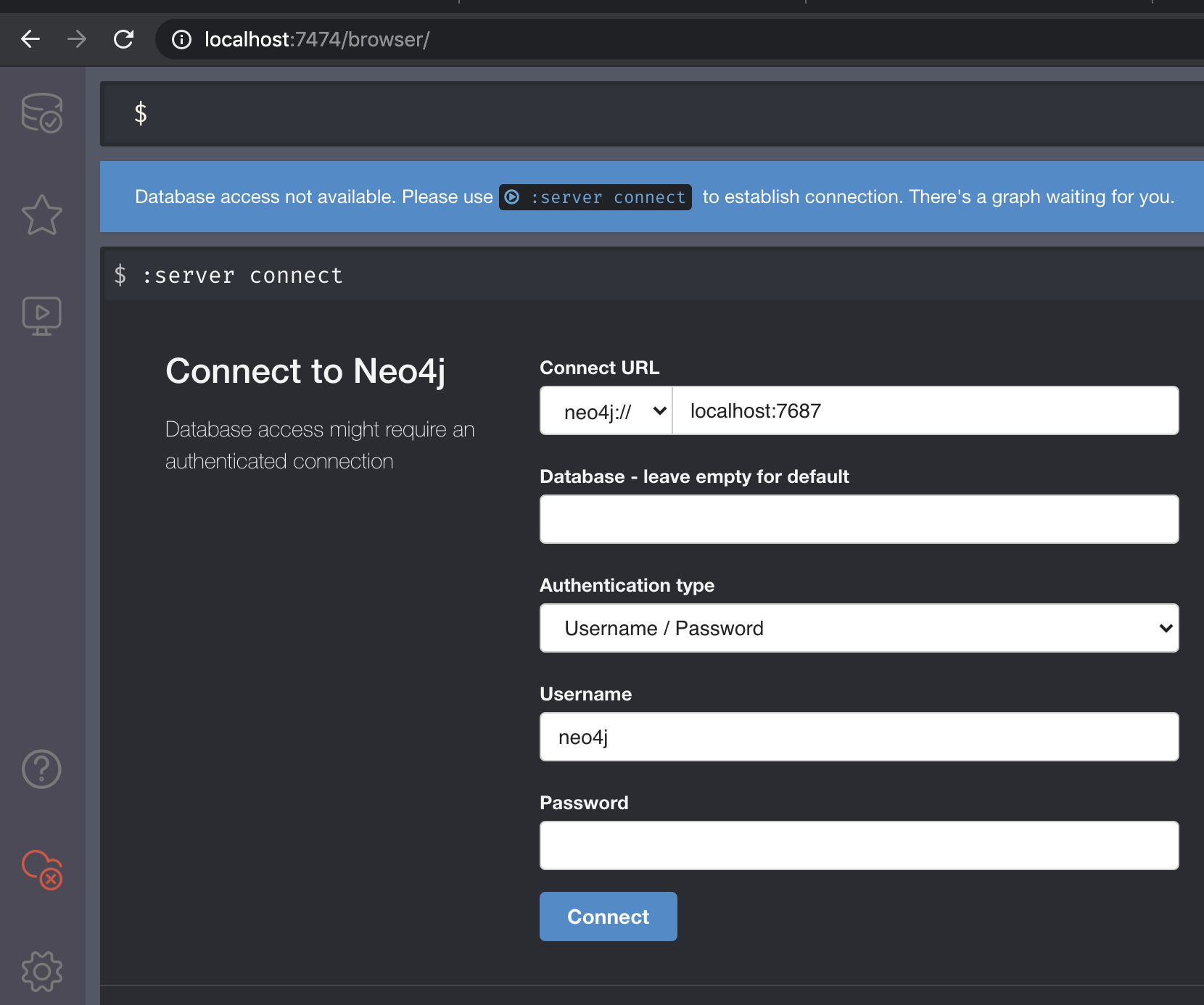
We will connect to the database using the No Authentication option.
We can also use another client tool: Neo4j desktop which is a Developer IDE for Neo4j instances.
Introducing Nodes and Relationships
With our installations completed, we will introduce the main concepts used to describe a data model in Neo4j before getting down to creating our data model. The main concepts of a data model in Neo4j are shown in this diagram:

We can see nodes grouped by labels and connected to other nodes with relationships. Both nodes and relationships have properties to specify additional attributes.
Node
We represent entities with Node. They are the first entities that we identify when creating our data model. Along with relationships, Node is one of the fundamental units that form a graph. Nodes can contain properties that hold name-value pairs of data.
Properties
Properties represent the attributes of the node and relationships. They are name-value pairs that are used to add qualities to nodes and relationships.
Node Label
We can assign roles or types to a Node using one or more labels. Labels are used to group nodes where all nodes having the same label belongs to the same group.
Relationship
We use a relationship to connect two nodes. A relationship must have exactly one relationship type.
We will explore these concepts further in the next section by creating a data model.
Creating a Data Model
Let us create the data model of a common use case of a customer placing an order in an e-commerce application:

The customer can place one or more orders and each order is composed of one or more order items.
We can describe this model in terms of entity relationships as having three entities:
- Customer.
- Order.
- Order Item.
and two associations:
- one-to-many relationship between customer and order entities.
- one-to-many relationship between order and order item entities.
Let us model this in our Graph Database.
Adding Nodes With Labels and Properties
Let us create one customer named "Annie" who is registered in our e-commerce application by running the below command in the Neo4j browser:
CREATE (customer1:Customer{name: 'Annie', mobile: '0987567876', email: 'annie@mydomain.com'})We get the following output after running this command:

As we can see from the output, we just created one node with a label of Customer and three properties of the node - name, mobile, and email.
The information about the customer is represented as a node. We will label all customer nodes in our e-commerce application with a common label of Customer.
The syntax that we have used to create the node is Cypher which is Neo4j's Graph Query Language. We represent a node with open and closed parentheses. In our example, we have used a variable customer1 for the node which is optional. This is followed by the label and properties to further qualify the node.
Adding Relationships
Let our customer "Annie" do some shopping and place an order to purchase a television set. To represent this let us first create a node for order and another node for the television set by running these commands in the Neo4j browser:
CREATE (order1:Order{orderID: 'ORD-001', date: '19-05-2021'})
CREATE (tv:OrderItem{itemName: 'Television', brand: 'samsung'})Running these commands gives the following output:

As we expected, we have created two more nodes:
- for the order with a label of Order and property
orderIDanddate. - for the order item with a label of OrderItem and property
itemNameandbrand.
To complete our data structure, we will connect these nodes by adding relationships. As explained earlier, a relationship connects two nodes and must have exactly one relationship type.
Let us connect the node of customer "Annie" with the node of her order by running the command:
MATCH
(a:Customer),
(b:Order)
WHERE a.name = 'Annie' AND b.orderID = 'ORD-001'
CREATE (a)-[r:PLACES]->(b)
RETURN type(r)Here we have used the MATCH clause of Cypher graph query language. The MATCH keyword works like SELECT in SQL. It is used to search for an existing node, relationship, label, property, or pattern.
Here we first locate the customer and order nodes with the MATCH and WHERE clause and then create the relationship named PLACES with another pattern ()-[]->().
We represent a relationship by open/close square brackets and use hyphens in combination with the nodes and relationships to represent a pattern.
The RETURN keyword is used to specify what values or results we want to return from a Cypher query. We can return nodes, relationships, node and relationship properties, or patterns from our query results.
The relationship is returned in the query output:

We will next create the relationship between order and orderItem node by running the command:
MATCH
(a:Order),
(b:OrderItem)
WHERE a.orderID = 'ORD-001' AND b.itemName = 'Television'
CREATE (a)-[r:CONTAINS]->(b)Here we are using a Cypher construct similar to the construct we had used for creating the relationship between Customer and Order nodes.
We get the output for the relationship created after running this query:

We have already used a good amount of Cypher syntax so far for creating the nodes and relationships of our data model. Please refer to the official developer guide for digging deeper inside Cypher.
With our data created, we will look at accessing this data from an application with queries written in Cypher which is Neo4j’s graph query language.
Application Integration
For using the Neo4j database in our applications, we need to connect to Neo4j from our application by using a driver library. Neo4j supports connection via Bolt or HTTP protocols.
Bolt is a binary protocol based on the PackStream serialization and supports the Cypher type system, protocol versioning, authentication, and Transport Layer Security (TLS). For Neo4j Clusters, Bolt provides smart client routing with load balancing and failover. The official drivers provided by Neo4j support connections to the database using the Bolt protocol.
The flow of control through an application unit goes like this:

Let's run through a sample Java program to see this flow.
We have added the Neo4j driver as a Maven dependency in our pom.xml:
<dependencies>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>4.2.5</version>
</dependency>
</dependencies>Here we have added a recent version 4.2.5 of the Neo4j driver: neo4j-java-driver .
Next, we created a class ProductRepository where we are accessing the Neo4j database using the driver: neo4j-java-driver.
package io.pratik.neo4japp;
import static org.neo4j.driver.Values.parameters;
import java.util.logging.Logger;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
import org.neo4j.driver.Result;
import org.neo4j.driver.Session;
import org.neo4j.driver.Transaction;
import org.neo4j.driver.TransactionWork;
public class ProductRepository implements AutoCloseable {
private static final Logger logger = Logger.getLogger(ProductRepository.class.getName());
private final Driver driver;
public ProductRepository(final String uri) {
// Instantiate the Neo4j driver with URI of database.
// We have disabled user authentication so so we don't
// need userID/Password here for authentication.
driver = GraphDatabase.driver(uri);
}
public String fetchProductByBrand(final String brandName) {
// Cypher query to find orderitem for a
// specific brand represented by the parameter $brand
final String QUERY_IN_CYPHER = "MATCH (n:OrderItem) "+
"WHERE n.brand = $brand " +
"RETURN n.itemName";
// Get the session handle inside a extended try block
try (Session session = driver.session()) {
// Start a read transaction
String resultItem = session.readTransaction(new TransactionWork<String>() {
@Override
public String execute(Transaction tx) {
// Run the query after passing the value of
// the brand parameter
Result result = tx.run(QUERY_IN_CYPHER,
parameters("brand",
brandName));
return result.single().get(0).asString();
}
});
System.out.println(resultItem);
return resultItem;
}
}
@Override
public void close() throws Exception {
driver.close();
}
/**
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
try (ProductRepository productRepository =
new ProductRepository("bolt://localhost:7687");){
String productName = productRepository.fetchProductByBrand("samsung");
logger.info("productName::"+productName);
}
}
}In this class, we are instantiating the driver in the constructor and fetching the order item data in the fetchProductByBrand method. We had created this data earlier by executing Cypher queries from the Neo4j browser.
When we run this class, we get this output in the console:
INFO: Direct driver instance 1938056729 created for server address localhost:7687 Television
INFO: productName::Television
INFO: Closing driver instance 1938056729
INFO: Closing connection pool towards localhost:7687We can see the output of our query - Television printed in the console log. We are closing the session at the end of the execution.
Sessions are bound to a transaction context. The session acquires the connection from the driver connection pool when we start the transaction by calling the readTransaction method on the session handle. The session releases that connection on commit (or rollback) of the transaction.
You can refer to the complete source code in my GitHub Repository.
Conclusion
Here is a summary of the topics we covered in this article:
- Relational database systems (RDBMS) are not very efficient in handling high volumes of connected data. So we need a graph database for fetching, creating, and manipulating data stored in the form of a graph data structure.
- A Graph is a data structure composed of two elements: a node and a relationship. Each node represents an entity (a person, place, thing, category, or another piece of data), and each relationship represents how the two nodes are associated.
- Neo4j database is an open-source, NoSQL, native graph database supporting ACID transactions.
- Neo4j database consists of a server to which we can connect using different types of clients over HTTP or Bolt protocols. We can use Neo4j browser and Neo4j desktop to connect to the database and execute queries written in Cypher language.
- We use Neo4j drivers to connect to the database from our application and run Cypher queries within a transaction scope running inside a session that holds the database connection.
I hope this article has given you an understanding of graph databases which should help you to consider using Neo4j or any other graph database for storing appropriate connected data in your applications.
Opinions expressed by DZone contributors are their own.
Trending
-
Boosting Application Performance With MicroStream and Redis Integration
-
Top Six React Development Tools
-
Orange Pi Cluster With Docker Swarm and MariaDB
-
Apache Kafka + Apache Flink = Match Made in Heaven
Comments