NoSQL in Plain English
NoSQL databases can't replace a general-purpose RDBMS or ad hoc queries. They're a scalable solution to support real-time data ingestion via a unique key, but beware of the limitations.
Join the DZone community and get the full member experience.
Join For FreeIn this article, I will describe NoSQL databases and explain when to deploy this powerful database solution. This is a "plain English" article, so I'll avoid resorting to jargon.
Why Not Use Hadoop?
While Spark SQL, Impala, and Hive are potential solutions for interactive analytic queries across petabyte-sized data sets, they have severe limitations:
- No random access to data: Hadoop provides no indexes or random access lookups on a single row. Instead, it is designed to summarize and present massive datasets at scale.
- Append-only: Although Hive supports update and delete operations, it's strictly limited, and for the most part, data can only be appended to an existing dataset.
What's Different About NoSQL?
Where fast random access and OLTP-like functionality are needed, the most sensible solution is a traditional relational database; but while processing semi-structured data or internet-scale throughput, there's an alternative database class available: the NoSQL database.
There are literally hundreds of options available, each with different strengths, but NoSQL databases tend to:
- Not use SQL: It's in the name. These databases have a custom-built query language, although many are accessible via other SQL tools, including Spark and Apache Drill.
- Support high-velocity workloads: They are built to process massive data velocity — tens of thousands of inserts per second across hundreds of nodes.
- Support massive data volumes: Many can automatically shard (spread out) data across a number of machines and support very fast retrieval of massive (petabyte) datasets with ease.
- Are implemented on a distributed system: To achieve high velocity and massive data volumes, they must scale out.
- Avoid a relational model: They tend not to support the highly flexible (but often performance-constrained) relational model. This means database design tends to be centered around efficient data access for a specific application rather than a general-purpose query solution. However, the benefits of performance, scalability, and throughput make this compromise worthwhile. This means NoSQL database design tends to be highly denormalized, and they will remain a relatively niche solution.
Note: NoSQL databases tend to be open-source (in most cases) and may run on Hadoop HDFS, although some databases also run stand-alone and independent.
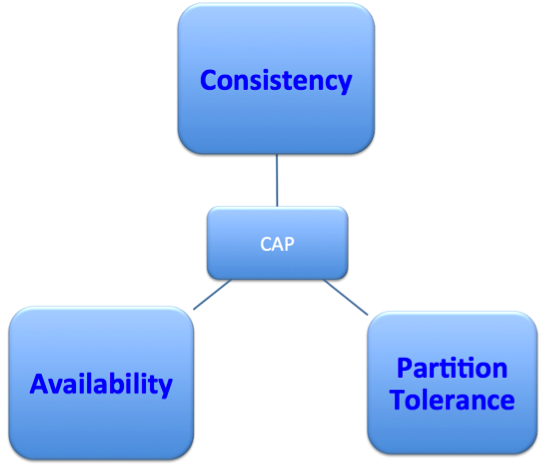
The CAP Theorem
OK, before you nod off to sleep, bear with me. This is a simple concept with practical implications for any big data project.
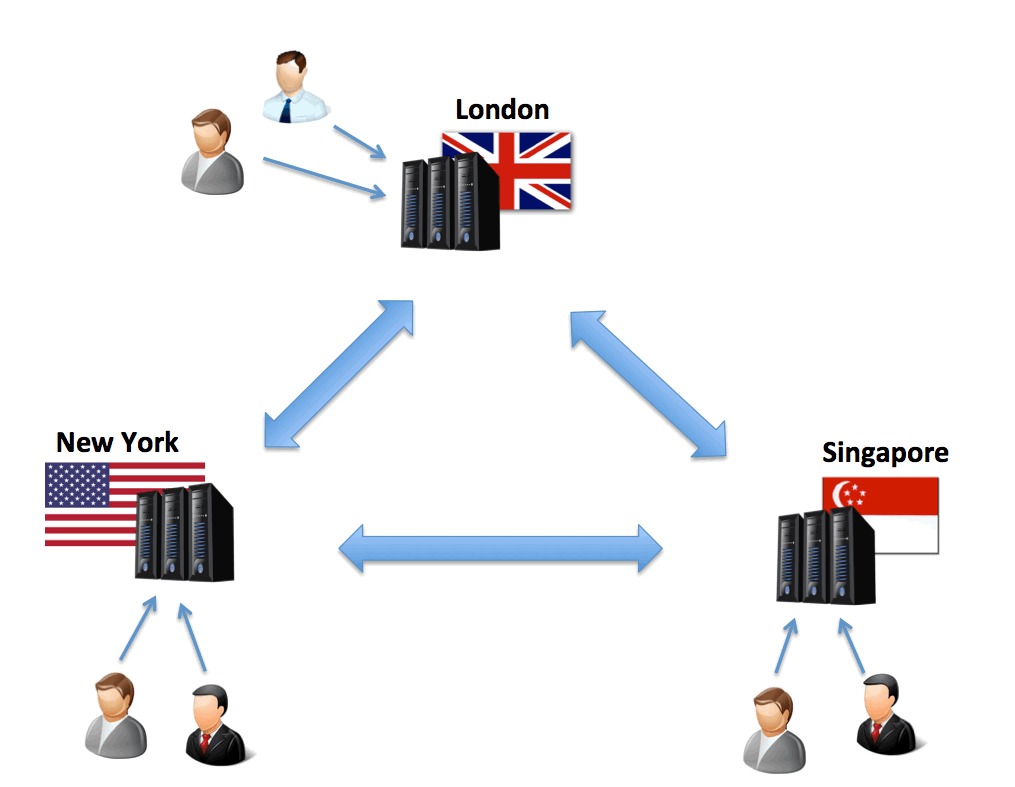
Let's take a typical big data architecture problem. Assume you're designing a sales support system for a globally distributed workforce in London, New York, and Singapore. You need to provide the latest sales totals by the customers to help support your clients. You need sub-second response times on a screen with a maximum transaction latency of 30 seconds. That means a transaction posted in London must be visible in Singapore within 30 seconds.
As we need sub-second response times, we need a cluster of machines at each of the three locations and with data replication between them.
We have three primary challenges:
- Consistency: Ideally, data in all three locations are consistent with each other. This means a sale posted in London is visible at the exact same instant in New York and Singapore. If it fails to complete, it's rolled back everywhere at the same instant.
- Availability: This is a mission critical system where downtime is not an option.
- Partition tolerance: If the link between any two data centers fails, the system must keep going. The entire Far East cannot stop accepting requests because the link to London fails.
Can you see the problem with the requirements above? They're partly mutually exclusive.
For example, if the link to Singapore fails, you cannot ensure transactions in Singapore are correctly reflected in London — the consistency requirement is broken. Likewise, if you insist on 100% data consistency, you cannot guarantee 100% availability if the link between data centers fails.
The CAP Theorem (first presented by Eric Brewer in 1998) indicates that you have three requirements. Put simply, you need to choose any two and compromise on the third.
A typical relational database is deployed on a single server and sacrifices partition tolerance in favor of consistency and availability. Likewise, any distributed NoSQL database must choose between two of the three.

Apache HBase
Based on a Google solution (BigTable), this is a column-based key-value store for very low latency processing on a massive scale. Random direct access is available via a single predefined key, and data changes can be automatically versioned as entries are updated.
Best suited to high volume transaction processing on massive datasets, HBase is used by Facebook to process 80 billion transactions per day on the Messenger application, with a peak throughput of two million operations per second. Like most NoSQL solutions, HBase is an excellent solution for high-volume OLTP processing, provided access paths to the data are direct access using a single key.
Conversely, HBase is a poor solution for data warehouse applications, which require analysis over millions of rows and where inserts tend to be batch operations with few updates.

Apache Cassandra
In terms of CAP, HBase favors consistency and partition tolerance over availability. HBase is a highly reliable solution, but it relies on a single master node to guarantee availability. However, as data is hosted on HDFS, there's almost zero risk of data loss, even after a hardware failure. Even a Master Node failure is normally recovered within seconds of a failover.
It's ironic that in Greek mythology, Cassandra had the gift of prophecy but was cursed by Apollo to always tell the truth, because Apache Cassandra compromises on data consistency.
Its primary strength is its guaranteed availability and its ability to be deployed in a geographically distributed solution. It does, however, support eventual consistency between nodes by default.
In the example of the analytic sales system above, it means transactions posted in New York will eventually be posted to London and Singapore, but there might be a slight delay. However, this means that if connectivity to New York is temporarily lost, each site will remain available and consistency automatically reestablished once the problem is resolved.
Clearly, if you're running a bank payments system and managing global financial transfers, this is not an appropriate solution — but most use cases don't demand 100% consistency every time. There is the option to insist upon consistency for a particular application (i.e. cash withdrawals), but this means those transactions will fail if connectivity to other machines is down. As above, the CAP rules apply.

MongoDB
Similar to HBase, Cassandra is designed for high transaction-processing velocity, and data can be replicated across geographically dispersed clusters, which suits this kind of use case. Cassandra has its own SQL-like interface (CSQL) but can also be accessed directly by Apache Spark.
Unlike most open-source NoSQL databases, MongoDB is built and supported by a corporation, so it benefits from full vendor support. Its name is a play on the word "humongous," and like many other NoSQL databases, it scales to petabyte-sized datasets.
The unique strength of MongoDB, however, is its ability to handle unstructured and semi-structured data; for example, text documents and JSON files. It's remarkably flexible and is capable of supporting multiple indexes (including document indexes).
Like HBase, it favors consistency and partition tolerance over availability, as it uses a single master node. It is, however, a highly reliable solution, and eBay uses it to deliver media metadata with an availability of 99.999%. It integrates well with Hadoop and Spark but it can also be deployed standalone.
Summary of Strengths
Apache HBase for consistency and high volume random access transaction processing over Hadoop HDFS.
Apache Cassandra for a highly available solution, especially in geographically distributed systems using data replication between clusters.
MongoDB for its remarkably flexible data model — excellent for processing unstructured documents, especially text and JSON. It's also supported directly by the vendor.
When to Consider NoSQL
NoSQL solutions are best considered when you have:
- Random access OLTP workloads, when you need to perform single row insert or update operations using primarily random access lookups as opposed to batch or micro-batch data append operations.
- Massive data volumes, when volume exceeds the ability to store and process the data on a single machine.
- Very high data velocity, when data arrives at a speed and volume that would overwhelm a single server.
- Massive scalability requirements, when your workload doubles (users or data volumes) every few months, which implies the need for a scale-out solution.
- Geographically dispersed users, when your users are globally dispersed and need very fast (low latency) access to data replicated across the globe.
When to Avoid a NoSQL Database
The economist Milton Friedman is quoted as saying "there's no such thing as free lunch," and that's true of almost any technology option, including the NoSQL database. Keep in mind the following limitations:
No join operations: NoSQL databases don't support the general-purpose relational data model, and there's typically no option available to perform join operations. This means database design tends to be centered around denormalizing data and building solutions for a specific use case.
Eventual consistency: Unlike a standard relational (or NewSQL) database, NoSQL solutions rely on eventual consistency. This means that they're not suitable for scenarios where there's money at stake. Any given read operation has risks in retrieving data information, and developers will need to code for these unusual circumstances in which the database can return potentially inconsistent results.
No SQL support: Although Apache Drill provides a SQL interface to many NoSQL databases, they tend to use an API interface, which can lead to a steep learning curve for some.
All the above means that NoSQL databases are not a suitable replacement for a general-purpose RDBMS or for ad hoc queries. As a fast, scalable solution to support real-time data ingestion via a unique key, they're a great solution, but beware of the limitations.
The NewSQL Alternative
While researching this article, I found an additional class of databases: the NewSQL database. This appears to have all the low latency, high velocity advantages of a NoSQL database with the added advantage of full ACID compliance and the flexibility of the relational data model. There are a number of options available including VoltDB, MemSQL, CockroachDB, and Google Spanner, and I'll cover them in another article.
Conclusion
You could argue (and Oracle will) that a relational database solution will satisfy most, if not all, of the above requirements, and the simplest solution is (by far) the best to adopt. However, it's no longer a case of "one size fits all," especially when your data sizes approach the petabyte scale.
Do keep in mind, though: keep it simple.
Thank You
Thanks for reading this far. If you found this helpful, you can view more articles on Big Data, Cloud Computing, Database Architecture and the future of data warehousing on my web site www.Analytics.Today.
Published at DZone with permission of John Ryan, DZone MVB. See the original article here.
Opinions expressed by DZone contributors are their own.
Trending
-
Spring Boot and Time Series Data in ScyllaDB
-
Zero Trust Network for Microservices With Istio
-
Implementing RBAC in Quarkus
-
Introduction to Elasticsearch
Comments